Workshop: Using and Developing Software for Keyness Analysis
Have you read about keyness measures and keyword analysis, but still have open questions? Do you know there are multiple keyness measures, but wonder which one is best for your research question? Or do you have experience using keyness, but wonder why different tools implement different measures? Then our workshop on “Using and Developing Software for Keyness Analysis” might be just the right event for you, as it will address these and many other related questions.”
The workshop will take place on February 27 (public event) and February 28 (closed event). The participation is free of charge and is possible both on-site and online. It is organized within the scope of the project “Zeta and Company” (https://zeta-project.eu/en/), conducted at Trier University, Germany and funded by the DFG.
The goal of this workshop is to foster exchange among tool developers and scholars from Computational Linguistics and Computational Literary Studies. The developers of stylo (Maciej Eder), Scattertext (Jason Kessler), TXM (Serge Heiden and Bénédicte Pincemin) and TEITOK (Maarten Janssen) will present their corpus analysis tools and the rationale behind their keyness implementation choices. The Zeta team will also present our implementation (pydistinto) and evaluation results. Finally, Stephanie Evert will present a keynote lecture on keyness to close the public programme.
The workshop will be divided into two parts and will last two half days, roughly from noon on the first day to noon the second day. The first part will be a public event that you can attend without restrictions, but registration is required. The second part will be a closed event, where the developers will discuss their further goals and ideas.
To apply for the workshop please send an email to Julia Dudar (dudar@uni-trier.de) providing your full name, institution, email-address and whether you will participate online or on site. Registration is open until February 15th.
We will be happy to meet you at our workshop.
Key information
Date and time (public event): February 27, 2023, 13:00 to ca. 19:15
The closed part of the event will take place on February 28, from 9:00 to 13:00.
Location: University of Trier, Germany, Gästeraum der Mensa. Please see indications below on how to find the venue.
Evening Keynote
Stephanie Evert: “Measuring Keyness”
In corpus linguistics, the notion of keywords refers to words (and sometimes also multiword units, semantic categories or lexico-grammatical constructions) that “occur with unusual frequency in a given text” (Scott 1997: 236) or a text collection, i.e. a corpus. Keywords are deemed to represent the characteristic vocabulary of the target text or corpus and thus have many applications in corpus linguistics, digital humanities and computational social science. They can capture the aboutness of a text (Scott 1997), the terminology of a text genre or technical domain (Paquot & Bestgen 2009), important aspects of literary style (Culpeper 2009), linguistic and cultural differences (Oakes & Farrow 2006), etc.; they give insight into historical perspectives (Fidler & Cvrcek 2015) and provide a basis for measuring the similarity of text collections (Rayson & Garside 2000). Keywords are also an important starting point for corpus-based discourse analysis (Baker 2006), where manually formed clusters of keywords represent central topics, actors, metaphors, and framings (e.g. McEnery et al. 2015). Since this process is guided from the outset by human understanding, it provides a more interpretable alternative to topic models in hermeneutic text analysis.
Keywords are usually operationalised in terms of a statistical frequency comparison between the target corpus and a reference corpus. Different research questions can be addressed depending on the particular constellation of target T and reference R, e.g. (i) T = a single text vs. R = a text collection (➞ aboutness), (ii) T and R = collections of articles on the same topic in left-leaning and right-leaning newspapers (➞ contrastive framings), or (iii) T = texts from a given domain or genre vs. R = a large general-language reference corpus (➞ terminology).
Although keyword analysis is a well-established approach and has been implemented in many standard corpus-linguistic software tools such as WordSmith (https://www.lexically.net/wordsmith/), AntConc (https://www.laurenceanthony.net/software/antconc/), SketchEngine (https://www.sketchengine.eu/), and CQPweb (Hardie 2012), it is still unclear what the “right” way of measuring keyness is (cf. the overview in Hardie 2014).
In this talk, I will discuss the different operationalisations of keyword analysis and survey widely-used keyness measures (Hardie 2014, Evert 2022). I will show how the mathematical differences between such measures can be understood intuitively with the help of a topographic map visualisation. I will address the difficulties of evaluating keyness measures and present a comparative evaluation on the task of corpus-based discourse analysis. Finally, I will summarise open questions and problems and speculate on directions that future research may take.
REFERENCES
Baker, P. (2006). Using Corpora in Discourse Analysis. Continuum Books, London.
Culpeper, J. (2009). Keyness: Words, parts-of-speech and semantic categories in the character-talk of Shakespeare’s Romeo and Juliet. International Journal of Corpus Linguistics, 14(1):29-59.
Evert, S. (2022). Measuring keyness. In Digital Humanities 2022: Conference Abstracts, pages 202-205, Tokyo, Japan / online. https://osf.io/cy6mw/.
Fidler, M. and Cvrcek, V. (2015). A data-driven analysis of reader viewpoints: reconstructing the historical reader using keyword analysis. Journal of Slavic Linguistics, 23(3):197-239.
Hardie, A. (2012). CQPweb – combining power, flexibility and usability in a corpus analysis tool. International Journal of Corpus Linguistics, 17(3):380-409.
Hardie, A. (2014). A single statistical technique for keywords, lockwords, and collocations. Internal CASS working paper no. 1, unpublished.
McEnery, T., McGlashan, M., and Love, R. (2015). Press and social media reaction to ideologically inspired murder: the case of Lee Rigby. Discourse and Communication, 9(2):1-23.
Oakes, M. P. and Farrow, M. (2006). Use of the chi-squared test to examine vocabulary differences in English language corpora representing seven different countries. Literary and Linguistic Computing, 22(1):85-99.
Paquot, M. and Bestgen, Y. (2009). Distinctive words in academic writing: a comparison of three statistical tests for keyword extraction. In Jucker, A., Schreier, D., and Hundt, M., editors, Corpora: Pragmatics and Discourse. Papers from the 29th International Conference on English Language Research on Computerized Corpora, pages 247-269. Rodopi, Amsterdam.
Rayson, P. and Garside, R. (2000). Comparing corpora using frequency profiling. In Proceedings of the ACL Workshop on Comparing Corpora, pages 1-6, Hong Kong.
Scott, M. (1997). PC analysis of key words – and key key words. System, 25(2):233-245.
Preliminary programm
| Time | Event |
| 13:00 | Meet and Greet |
| 13:30 | Welcome / Opening Remarks (Christof Schöch) |
| 13:45 | “Computing specificities in TXM: philological, NLP and corpus configuration considerations” (Serge Heiden) |
| 14:15 | “Scatterchron: visualizing diachronic or multi-class corpora in whole and parts” (Jason Kessler) |
| 14:45 | Coffee break |
| 15:15 | ‘Zeta and Company’ (Keli Du, Julia Dudar) |
| 15:45 | “Words that (might) matter, or keywords extraction using ‘stylo’” (Maciej Eder) |
| 16:15 | Short break |
| 16:30 | “Keyness in TEITOK: attempts, problems, and limitations” (Maarten Janssen) |
| 17:00 | “ Fishing for Keyness. The Specificity Measure in Textometry” (Bénédicte Pincemin) |
| 17:30 | Break |
| 17:45 | Evening keynote: “Measuring Keyness” by Stephanie Evert (hybrid via Zoom) |
| 18:45 | End of the academic programme |
Abstracts
Jason Kessler: “Scatterchron: visualizing diachronic or multi-class corpora in whole and parts”
This talk addresses the problem of visualizing how a sequence of texts changes over time. While there are intuitive and established ways of visualizing term differences between two text categories (e.g., Scattertext [Kessler, 2017]), approaches to visualizing diachronic differences become more complicated as the number of categories or timesteps increases.
To address this, I introduce Scatterchron, built on the Scattertext framework and which draws from ideas of the Parallel Tag Cloud (Collins et al., 2009) and PyramidTag (Knittel et al., 2021) data visualizations. It combines an interactive, simplified Parallel Tag Cloud-type visualization with a scatterplot showing dispersion, correlation, frequency, or average time position metrics. The parallel tag cloud displays key terms listed vertically at each time step. Clicking on the terms in the cloud or the scatterplot shows summary statistics, their variation in use at different time steps, and examples of their use in context.
A novel dispersion metric, Residual DA, is introduced, normalizing Burch’s DA of a term for its expected value given its frequency. Finally, we will discuss strategies for combining time steps to improve the readability of the visualization. In addition to unigrams, nearly any linguistic feature can be used, including n-grams, lexicon membership, lexico-syntactic extraction patterns, etc. It will be available at https://github.com/JasonKessler/KeynessToolsTalk
Serge Heiden: “Computing specificities in TXM: philological, NLP and corpus configuration considerations”
Given 4 parameters – (f) the number of occurrences of a word in a sub-corpus, and (F) in the whole corpus, (t) the total number of words in the sub-corpus, and (T) in the whole corpus – the specificity statistical measure calculates the surprise of observing such a high (or low) number of occurrences in the sub-corpus compared to the whole corpus. It was designed by Pierre Lafon in 1980 and is currently implemented in the ‘textometry’ R package. The TXM platform implements this measure through a number of mechanisms that help the interpretability of its results. First of all, taking into account the XML-TEI encoding of the sources allows us to choose the fineness of the contexts in which words appear by allowing us to distinguish various granularities of sub-corpora throughout the texts, in addition to the usual contrasts between textual units – such as, for example, the utterances of the various characters in a play or of the different genders of these characters – as well as various textual plans to be taken into account, such as being able to temporarily ignore the content of notes or titles. Then, the extraction by a flexible search engine of single or composite lexical observables (words) based on automatic or semi-automatic linguistic properties (lemmas, parts of speech…) allows to easily vary the lexical observation level. Finally, the tools for creating corpus configurations (partitions and sub-corpora) make it possible to efficiently organize the contrasts studied.
Bénédicte Pincemin: “Fishing for Keyness. The Specificity Measure in Textometry”
The Specificity measure (Lafon, 1980) is one of the core analytic features in textometric software like TXM, IRaMuTeQ, Trameur, Hyperbase, DtmVic, Lexico. It implements a precise and straightforward modeling of word frequency variation, and adopts a convenient notation that converts probabilities into magnitudes. This operational clarity is an asset in the Humanities from a hermeneutic point of view, and it helps understand and manage the model limitations. The Specificity measure does not modelize keyness, nor language, but it provides a meaningful benchmark for frequency evaluation. As a Fisher’s exact test, it is valid over the entire frequency range, and it does not require any additional confidence test. The Specificity measure applies a bag-of-words reduction, however this may be overcome by using Specificity in combination with other text analysis tools or in the context of a rich corpus encoding, as can be illustrated within TXM software.
Reference: Lafon, Pierre (1980). Sur la variabilité de la fréquence des formes dans un corpus. Mots, 1, 127-165. http://www.persee.fr/web/revues/home/prescript/article/mots_0243-6450_1980_num_1_1_1008
Maarten Jannsen: “Keyness in TEITOK: attempts, problems, and limitations”
During the PostScriptum project, where TEITOK stems from, keyness is probably the major module that was very much desired by the team, but which we failed to implement. In this talk, I will discuss the various attempts we made to implement a (generalized notion of) keyness in TEITOK, the problems they present, and why no implementation of keyness is currently part of the TEITOK distribution. To end on a more positive note, I will discuss some recent developments that could reopen the door for a full-fledged keyness module in TEITOK.
Julia Dudar & Keli Du: Zeta and Company
Statistical measures of distinctiveness (keyness measures) allow researchers to extract features (e.g., words or parts-of-speech) that are characteristic or “distinctive” for a given group of texts compared to another group of texts. In order to reach a deeper understanding of measures of distinctiveness, we analyzed a significant range of existing measures of distinctiveness to determine and compare their statistical properties and integrate them into a joint conceptual model (https://doi.org/10.5281/zenodo.5092328). Based on this model and code from pyzeta (https://github.com/cligs/pyzeta), we have developed the Python package pydistinto (https://github.com/Zeta-and-Company/pydistinto), which facilitates the use of nine measures that can be used for contrastive text analysis. Furthermore, we assessed and compared these measures’ performance using different evaluation strategies. In this talk, we will present our conceptual model and Python package and report on our experiments and results of our evaluation of different measures of distinctiveness.
Maciej Eder: “Words that (might) matter, or keywords extraction using ‘stylo’”
The presentation will revolve around theoretical considerations of keyness and keywords, namely the question what an ideal set of keywords should represent in a text. This will be followed by a brief comparison of a few keywords extraction methods. Special attention will be paid to the implementation of the Zeta method in the R package ‘stylo’. Future perspectives of implementing other keywords methods will be also discussed.
Additional workshop
In addition to the Keyness Workshop, we are happy to offer an introduction to Scattertext by Jason Kessler! The workshop will take place on Tuesday, 28.02.2023 from 14–16 o’clock in the Gästeraum of the canteen. The abstract can be found below:
Jason Kessler: “It was obvious in retrospect: interactive language visualization with Scattertext”
Scattertext is a Python package designed to make it easy to produce interactive visualizations of a corpus. Interactive visualization helps not only finding associated keyphrases but, by looking at keywords in context, understanding why they are associated.
The problem of visualizing how a foreground corpus differs from a background corpus will be the focus of the first part of the tutorial. This was the original use case of Scattertext, and we will see how simple term frequency plots can yield interesting category-associated terms. We will also look at ways of plotting term distinctiveness measures and include instructions on adding a custom measure.
We will also discuss how to visualize different kinds of features beyond unigrams, including phrase-like n-grams, lexicons, and phonemes. Special attention will be paid to reducing the set of features to ensure the visualizations render quickly.
We will also address the problem of focusing keyness analysis on terms with similar meanings or usage through embedding techniques such as word2vec or prebuilt embeddings.
The second half of the tutorial will focus on more experimental aspects of Scattertext.
Visualizing keyness for multiple categories of text in the same visualization is a difficult problem. We will look at category-based dispersion plots and use multiple interactive scatterplots to examine two-dimensional projections of category and term embeddings.
Finally, we will explore how to use Scattertext to see changes in a corpus over time. We will see how a combination of parallel tag cloud-like visualizations and various types of scatter plots, including correlations, dispersion, and average-time based.
The tutorial will consist of Jupyter notebooks and slides discussing related work. The material will be available at https://github.com/JasonKessler/KeynessToolsTalk as the date of the tutorial approaches.
Itineraries
How to arrive on campus
To easily get to Trier University’s campus I (main campus), it is recommended to use public transport (buses). Depending on where you are starting from, different bus lines can be taken. It is also possible to arrive by car and park near the campus. You can find out more about your own directions here.
- Start point A: Main (train) station (“Hauptbahnhof”)
- Daytime:
- Line 3 (direction Kürenz/Lud.-Erhard-Ring): every ten minutes, get out at the stop “Universität”
- Line 231 & 31 (direction Pluwig/Bonerath): every half hour, get out at the stop “Universität Süd”
- Early morning/evening/weekend:
- Line 83/88 (direction Tarforst): get out at the stop “Universität”
- Line 81 (direction Tarforst): every half hour, get out at the stop “Universität Süd”
- Daytime:
- Start point B: City centre (“Porta Nigra, Bussteig 2”)
- Daytime:
- Line 3 (direction Kürenz/Lud.-Erhard-Ring): every ten minutes, get out at the stop “Universität”
- Line 6 (direction Tarforst): every ten minutes, get out at the stop “Universität Süd”
- Early morning/evening/weekend:
- Line 83/88 (direction Tarforst): get out at the stop “Universität”
- Daytime:
How to get from the bus station to the “Gästeraum der Mensa”
Pro-Tip: You can put “Mensa der Universität Trier, University of Trier, 54296 Trier” into Google Maps to get hands-on directions.
Starting at bus station “Universität”
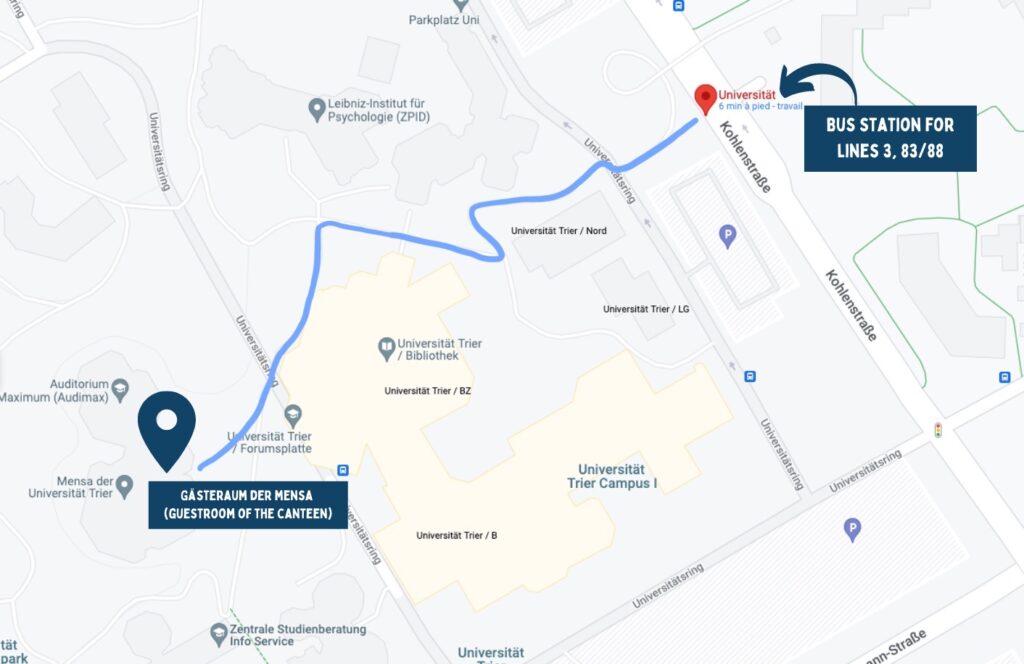
To get to the Gästeraum der Mensa (guest room of the canteen), when you get out of the bus, walk straight ahead (left path next to the bridge) and follow the way indicated by the signs in place. You will pass the N building on the left side, then the E and D buildings on the right. You then have to turn left and cross the bridge with the yellow railing after which you will pass the library on the left side (green building) and arrive on the Forumsplatte from where you can directly access the canteen with the Gästeraum.
Starting at bus station “Universität Süd”
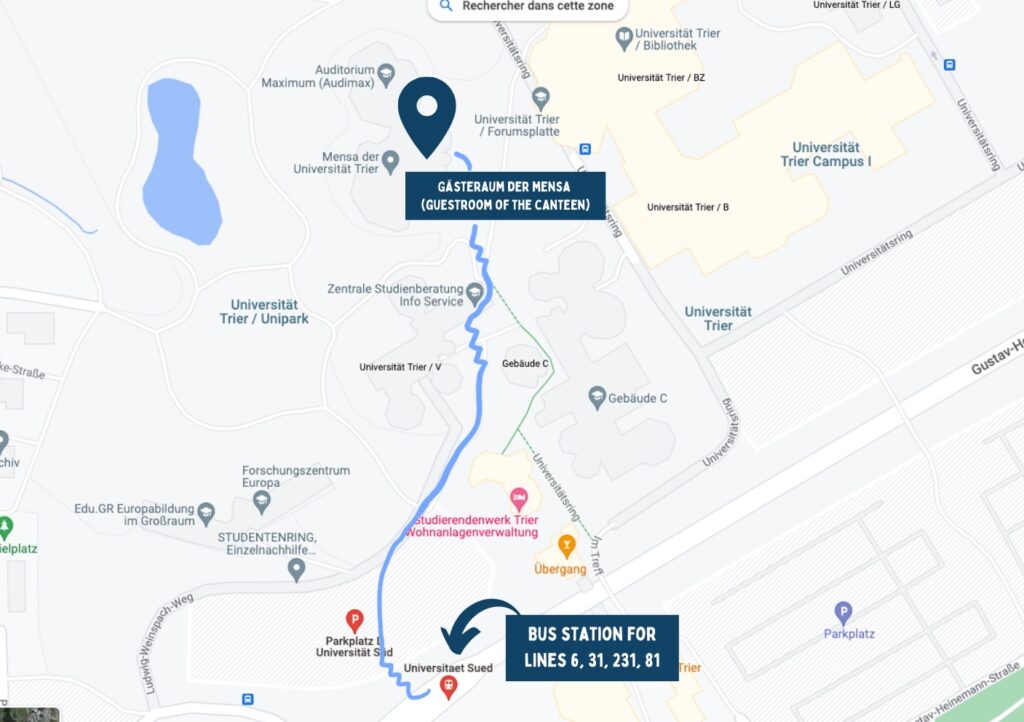
To get to the Gästeraum der Mensa (guest room of the canteen), when you get out of the bus, turn right and climb the stairs that lead up to a parking lot. The building you’ll see first is the DM-building. You need to pass it and follow the path until you arrive at another staircase you have to climb to arrive at the V building. In front of the V building, you can choose between several staircases; we recommend using those at your left-hand side (near a little pond), then you’ll get out almost directly in front of the canteen.